


In an age marked by the rapid evolution of information technology and communication, the emergence of social media platforms has revolutionized the way individuals interact and express themselves. The advent of these platforms has facilitated the dissemination of ideas and thoughts across the globe within seconds, fostering a virtual space for dialogue and engagement on an unprecedented scale. However, amidst this technological revolution, a darker trend has emerged – the proliferation of offensive and hate speech content.
The widespread availability of social media platforms has provided individuals with a platform to exercise their right to freedom of speech. However, this freedom has been exploited by some to propagate hate speech, aimed at inciting violence, spreading misinformation, and perpetuating discrimination. The consequences of such behavior are far-reaching, posing a direct threat to the basic human rights of individuals and undermining the principles of tolerance and inclusion in society.
In response to this growing challenge, researchers and technology experts have devoted significant efforts to developing tools and algorithms aimed at detecting and mitigating abusive content on social media platforms. While much progress has been made in languages with abundant linguistic resources, such as English, languages with limited resources, such as Urdu, have remained largely underrepresented in hate speech detection research. This neglect is primarily attributed to the lack of large-scale datasets and the inherent complexities of linguistic analysis in low-resource languages.
Our research seeks to address this gap by proposing a comprehensive methodology for the detection of abusive content in Urdu, coupled with a demographic analysis of an indigenously developed dataset. The methodology encompasses two main components: the collection and labeling of a unique unlabeled Urdu dataset sourced from Twitter, and the application of machine learning and deep learning algorithms for content classification. By leveraging cutting-edge technologies and methodologies, our research aims to shed light on the nuances of hate speech detection in Urdu, paving the way for more effective and inclusive strategies for combating online abuse.
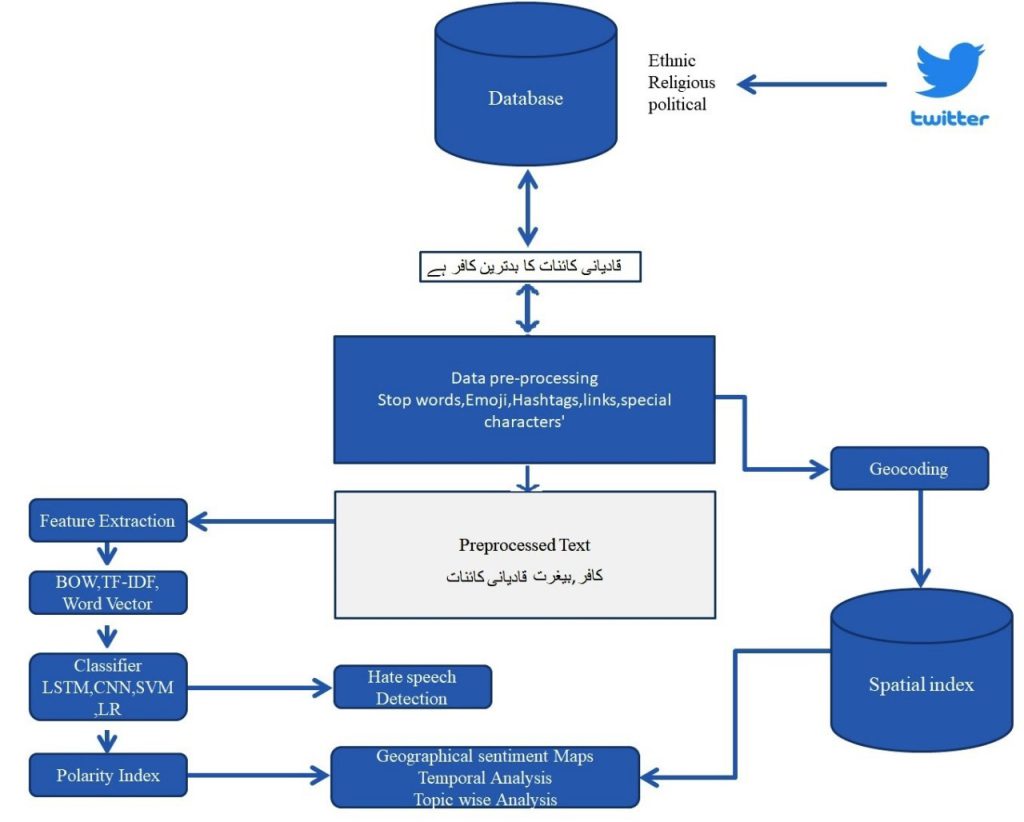
The first step in our methodology involves the collection of a substantial dataset comprising 0.2 million tweets, meticulously curated from across the 36 districts of Punjab, Pakistan, spanning from 2018 to April 2022. This dataset serves as the cornerstone of our research, providing a rich and diverse source of linguistic data for analysis. The tweets are collected using a web scraping tool named snscraper, which enables us to extract real-time data from Twitter, capturing the dynamic nature of online discourse.
Once collected, the dataset is meticulously labeled into three target classes: Neutral, Offensive, and Hate Speech. This labeling process is crucial for training machine learning algorithms to accurately classify and identify abusive content. However, annotating such a large dataset is a time-consuming and labor-intensive task, requiring careful attention to detail and a nuanced understanding of the cultural and linguistic nuances of Urdu.
Following data cleaning procedures to remove noise and irrelevant information, we proceed with the feature extraction process. Traditional feature extraction techniques such as Bag-of-Words (BoW) and Term Frequency-Inverse Document Frequency (tf-idf) are employed, alongside more advanced techniques such as word and character n-grams and word embedding using Word2Vec. These techniques enable us to capture both the semantic and syntactic features of the text, providing a comprehensive representation of the dataset.
With the dataset prepared and features extracted, we proceed to train and evaluate machine learning and deep learning algorithms for content classification. We employ a combination of traditional machine learning algorithms, including Support Vector Machines (SVM) and Logistic Regression, as well as state-of-the-art deep learning techniques such as Long Short-Term Memory (LSTM) and Convolutional Neural Networks (CNN). These algorithms are trained on the labeled dataset, with performance evaluated based on metrics such as F-score and accuracy.
Our results indicate that while traditional machine learning algorithms perform reasonably well, achieving moderate levels of accuracy and F-score, deep learning algorithms exhibit superior performance, particularly when applied to large datasets. LSTM emerges as the top-performing algorithm, achieving an impressive F-score of 64 and an accuracy of 93. These findings underscore the effectiveness of deep learning techniques in capturing the complex patterns and nuances inherent in hate speech detection, especially in languages with limited linguistic resources like Urdu.
However, despite the promising results achieved by deep learning algorithms, our research also highlights several challenges and limitations. Class imbalance, data sparsity, and high dimensionality emerge as significant obstacles, affecting the performance and generalizability of the models. Moreover, we encountered difficulties related to overfitting, underscoring the need for robust error analysis and model refinement processes.
Looking ahead, our research lays the groundwork for future exploration and innovation in the field of hate speech detection in Urdu. Addressing the challenges identified in our research, such as data sparsity and high dimensionality, will require the development of advanced techniques and methodologies tailored to the unique linguistic and cultural characteristics of Urdu. Additionally, efforts should be directed towards incorporating advanced features to distinguish between different degrees of language, such as sarcasm, implicit hate speech, and variations in language sense.
Furthermore, future research should prioritize the analysis of minority classes and hidden patterns within the dataset, ensuring a more inclusive and accurate detection framework. The development of a comprehensive sentiment dictionary for Urdu, coupled with advanced embedding features, will be crucial for enhancing the effectiveness and accuracy of hate speech detection models. Moreover, the implementation of linguistic techniques such as word segmentation will be essential for improving the language processing capabilities of the models.
In conclusion, our research represents a significant step forward in addressing the challenge of hate speech detection in Urdu. By leveraging cutting-edge technologies and methodologies, we have developed a comprehensive framework for detecting abusive content on social media platforms, laying the foundation for more effective and inclusive strategies for combating online abuse. However, challenges remain, and further research is needed to overcome obstacles such as data sparsity, class imbalance, and high dimensionality.
Moving forward, we call for continued collaboration and innovation in the field of hate speech detection, with a focus on addressing the unique challenges posed by low-resource languages like Urdu. By harnessing the power of advanced technologies and methodologies, we can strive towards a safer and more inclusive online environment for all users, free from the scourge of hate speech and online abuse. Together, we can build a brighter future for social media, one where freedom of expression is upheld, and tolerance and respect are the guiding principles of online discourse.
The author is an Associate Professor at Military College of Signals (MCS), National University of Sciences and Technology (NUST). He can be reached at yawar@mcs.edu.pk.
Research Profile: https://bit.ly/3ViH7f9

![]()


