



Robust and efficient Machine Learning (ML) algorithms are the crux of attention in the image/video and speech processing community. The purpose of this project is to develop an intelligent object detection system to categorize various objects of interest in the daily life. Hence, provide a smart vision capability to visually impaired people.
Mostly, the currently available supportive tools for vision impairment are based on obstacle avoidance rather than obstacle/object detection and then categorization. In other words, this just avoids the use of white stick but cannot contribute more towards development of a critical sense i.e., vision.
The main challenge in this project is to devise a machine learning algorithm that should be capable of recognizing the objects from video/image with high accuracy in a highly variable environment. This is achievable if the ML system learns and recognizes the object of interest viewed through arbitrary angle and position i.e., learn to capture the unique and abstract representation of object. For example, a cell phone or a cup placed on the table should be recognized regardless of its size, shape and orientation.
Deep neural architectures have gained a prominent place in the picture of machine learning algorithms. Marked by the ability of extracting characteristic and invariable feature of an object, they are amongst the state-of-the-art in various applications related to image or object recognition/categorization.
The aim is to design a dedicated deep neural architecture and employ that in a form of portable yet wearable device using small video capturing cameras. The end product should give the information about the type and distance of the object from a user. Indeed, this can be realized with conventional image processing together with the well-learned ML system.

The project has the following objectives.
- To develop an Electronic Aid System (ETA) based on stereo cameras and apply image processing techniques for object detection in the acquired images.
- To design and develop deep learning architecture for object recognition under high variability yielding better performance as compared to the state-of-the-art. The variability is defined as the variation in size, shape, orientation, light intensity and noise in the captured image or video frame.
- To optimize the coding of the proposed deep learning algorithm to make them suitable for portable computing hardware for real-time object recognition.
- To develop a portable vision system using stereo camera and employing Raspberry Pi/ODROID computer for the required computation in step-1 and 3.
The methodology involves, collecting large-scale image dataset with annotated object classes to train YOLO deep architecture for generic object detection. ImageNet and COCO datasets are employed for this task.
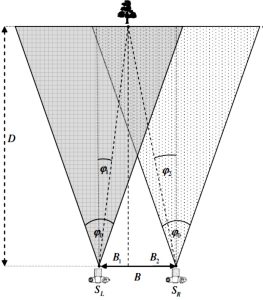
The YOLO system is optimized and fine-tuned for real-time inference in Raspberry Pi 4 achieving up to 5 FPS. A sample performance is depicted in the Demo Video. The YOLO system is input using one of the images captured using stereo camera (Intel RealSense) to detect object in the current video frame. While using the triangulation principal, a disparity map is calculated to estimate the distance of detected objects in that frame. The distance is then communicated to the user via earphones and text-to-speech (TTS) engine.

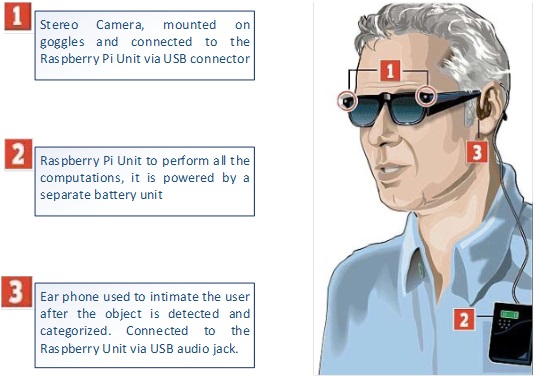
The entire ETA system is portable and powered by LiPo battery to support the voltage and current requirements of Raspberry Pi and camera. For TTS, wireless Bluetooth earphones are used which are interfaced with Raspberry Pi via Bluetooth adaptor.
The functioning involves following steps:
- User presses a button and interrupt is generated to command Raspberry Pi to read the current video frame.
- The YOLO system detects the objects (out of 100 classes).
- The distances of the detected objects are calculated and communicated to the TTS system.
- The TTS system makes the user aware about the class of detected object along with the approximate distance.
- Using this functioning scheme, a user may navigate and perform desired actions.
Video Demonstration
The author is a Tenured Associate Professor, in Department of Electrical Engineering, at School of Electrical Engineering and Computer Sciences, National University of Sciences and Technology (NUST). He can be reached at ahmad.salman@seecs.edu.pk.
Research Profile: https://bit.ly/3L7SHDy

![]()


