According to the World Health Organization, over 5% of the global population—an estimated 430 million people—live with hearing or speech impairments. Among them, more than 70 million individuals rely on approximately 300 distinct variants of sign languages as their primary means of communication, as reported by the World Federation of the Deaf.
Sign languages are not merely hand gestures—they are rich, structured visual languages with their own grammar, syntax, and intricacies. Expressed through the spatiotemporal dynamics of hands, facial expressions, and body movements, sign languages differ fundamentally from spoken or written languages. This structural gap often leads to a significant communication barrier between the Deaf and hearing communities.
Enter the “Gestures to Text” revolution—a cutting-edge AI-powered solution that aims to translate sign language into text in real-time. Our research focuses on building novel, graph neural network-based architectures that intelligently capture the spatiotemporal relationships of human skeletal movements. By modelling the natural connectivity of joints and bones, these lightweight and efficient models push the boundaries of sign language understanding.
This technology is more than an innovation—it is a mission to reduce inequalities, enable seamless communication, and empower millions who have long remained unheard. Here’s how we’re doing it—and why it matters now more than ever.
Research Gap & Challenges:
Despite the remarkable progress in Sign Language Recognition (SLR), the task remains inherently complex. Sign languages are defined by a limited set of visual articulators—including handshapes, orientations, movements, and facial cues—which often results in visually similar or indistinguishable signs. This creates a major hurdle for AI models, which struggle to accurately differentiate signs that appear almost identical, especially across different signers or contexts.
At the heart of this challenge lies the difficulty of extracting discriminative spatiotemporal feature. As a result, researchers have explored various input modalities—such as appearance-based (RGB), skeleton-based (pose), and hybrid methods—to overcome this gap.
However, these State-of-the-art (SOTA) methods are not without limitations:
- Excessive Complexity: Many models are over-parameterized and computationally heavy, making real-time deployment impractical.
- Limited Receptive Fields: These models often emphasize short-range joint connections, thereby neglecting long-range dependencies—an essential aspect for accurately interpreting complex or overlapping signs.
A Novel Approach:
To address these gaps, we propose a novel architecture: Multi-Scale Efficient Graph Convolution Network (MSE-GCN).
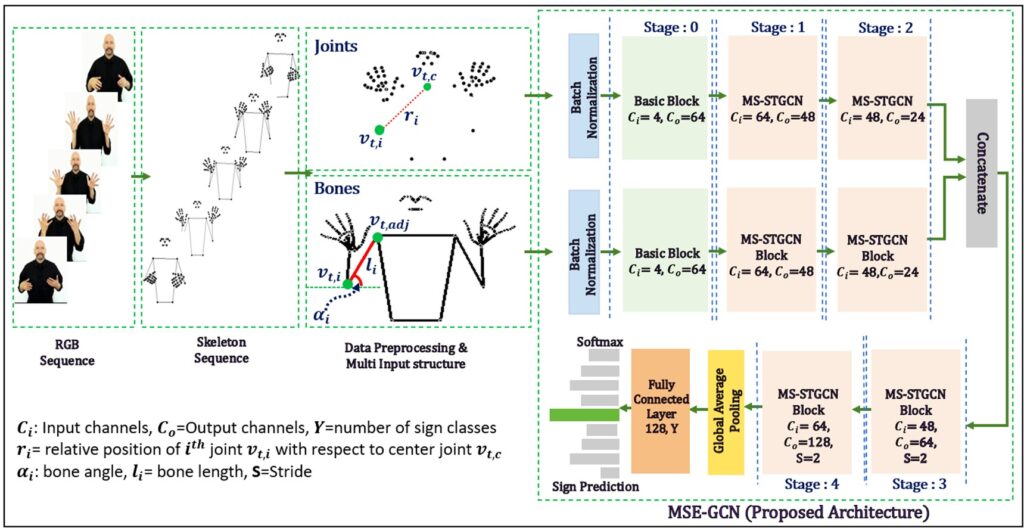
Our model is designed for accuracy, speed, and computational efficiency, achieved through a series of innovations:
- Multi-Scale Separable Convolutions: By employing separable convolutions across multiple spatial and temporal scales, the model captures both fine-grained and broader motion patterns, enhancing its ability to understand gestures over time.
- Multi-Branch Network with Early Fusion: This setup allows diverse spatiotemporal features to be learned in parallel and integrated early, improving feature richness and recognition accuracy.
- Spatial-Temporal Joint-Part Attention (ST-JPA): Our novel hybrid attention module intelligently focuses on the most relevant body parts and critical joints in the sign sequence, frame by frame, enhancing the model’s ability to distinguish subtle variations in complex signs.
Why It Matters: Speed, Accuracy, and Scalability in Sign Language Recognition
Faster Recognition: Leveraging human joints and bones as a graph structure, the system ensures low computational cost and real-time inference, making it ideal for live applications.
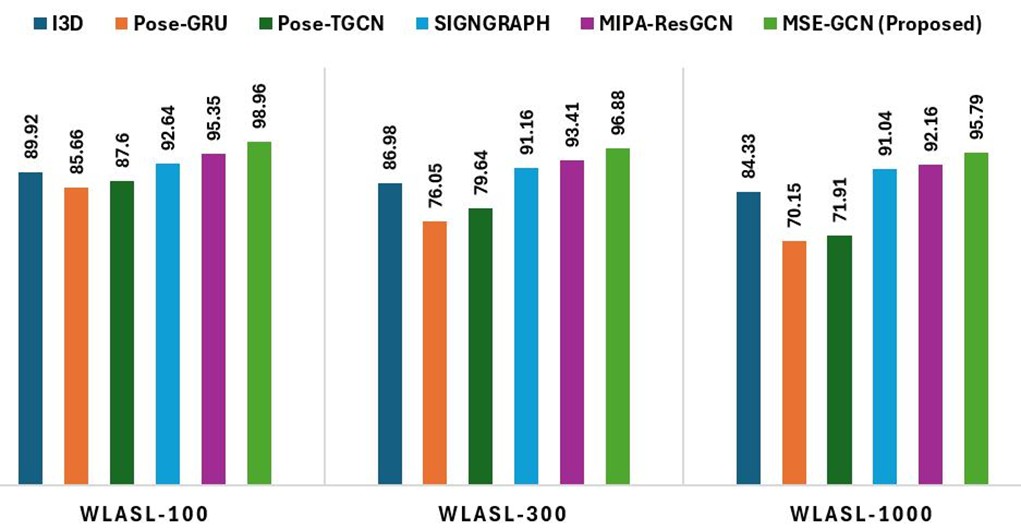
Higher Accuracy: Our architecture outperforms SOTA methods with:
- +9.92% over skeleton-based models
- +3.84% over RGB-based models
When tested on 1,000 American Sign Language (ASL) signs, capturing both inter-class differences and intra-class similarities. It also performs well to Brazilian and Argentinian Sign Languages.
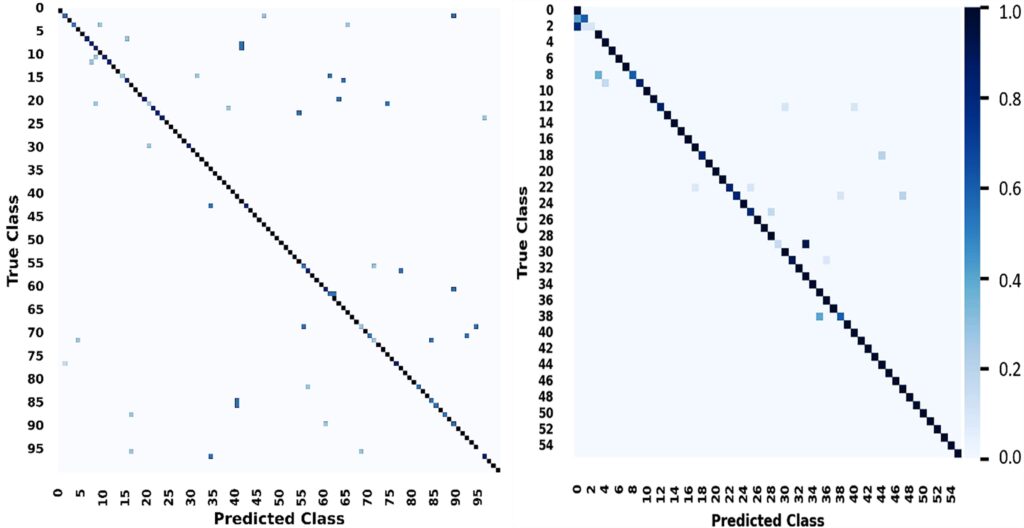
Visual Explanations: The system provides interpretable attention maps, highlighting the most relevant joints and body parts during sign recognition.
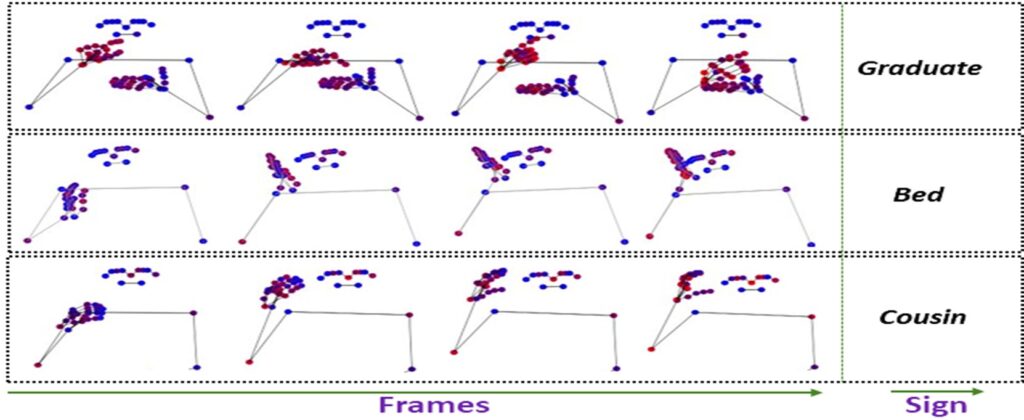
Scalable Architecture: Demonstrates strong scalability across growing dataset sizes—ready for large-vocabulary and multilingual sign language systems.
A more Inclusive Future for Speech Impaired and Hard-of-Hearing:
Our work envisions a world where communication is barrier-free for everyone—especially the 70+ million sign language users worldwide. By combining AI and advanced gesture recognition, we’re making real-time sign language understanding more accessible, accurate, and scalable.
This technology empowers:
- Speech-impaired individuals to express themselves freely in real-world settings.
- Educators and interpreters to bridge communication gaps effectively.
- Developers and researchers to build next-gen inclusive systems for public services, education, healthcare, and beyond.
It’s not just a technological breakthrough—it’s a step toward digital equality and a more inclusive society where every voice, spoken or signed, is heard.
References:
- Naz, Neelma, Hasan Sajid, Sara Ali, Osman Hasan, and Muhammad Khurram Ehsan. “MSE-GCN: A Multiscale Spatiotemporal Feature Aggregation Enhanced Efficient Graph Convolutional Network for Dynamic Sign Language Recognition.” IEEE Transactions on Emerging Topics in Computational Intelligence (2024).
- Naz, Neelma, Hasan Sajid, Sara Ali, Osman Hasan, and Muhammad Khurram Ehsan. “MIPA-ResGCN: A multi-input part attention enhanced residual graph convolutional framework for sign language recognition.” Computers and Electrical Engineering 112 (2023): 109009.
- Naz, Neelma, Hasan Sajid, Sara Ali, Osman Hasan, and Muhammad Khurram Ehsan. “Signgraph: An efficient and accurate pose-based graph convolution approach toward sign language recognition.” IEEE Access 11 (2023): 19135-19147.
The author is an Assistant Professor at School of Electrical Engineering and Computer Science (SEECS), National University of Sciences and Technology (NUST). She can be reached at [email protected].

![]()